比 AlphaGo 更复杂,最强日本麻将 AI 是怎么炼成的
“我突然想起了一句话,神仙怎么打都是对的。”
“这个 AI 的牌效不是一般凤凰(有一定实力的玩家)能摸清的,人名字就是 super phoenix(超级凤凰)。”
“感觉 ai 的打法都不太能被推理完全,这种基于训练的对某种特征做出的反应对于人类来说就是迷啊…”
这些评论来自于 B 站上一个系列的视频,视频主角是一个名为 Suphx(意为 Super Phoenix)的麻将 AI。2019 年 6 月,有创作者开始制作 Suphx 牌谱的视频。上传到 B 站后,引起了不少麻将爱好者的讨论。
在多数评论里,Suphx 被称为“最强日麻人工智能”。

事实上,不止是国内的 B 站,当时 Suphx 的声名已经传遍了日本麻将界。
神秘的最强日麻 AI
2019 年 3 月起,Suphx 获批进入专业麻将平台“天凤”。短短四个月内,Suphx 在该平台疯狂对战 5760 次,成功达到十段,从而在日本麻将界声名大噪。
麻将在中国群众基础深厚、普及率高,有“国粹”之称,但民间流行的麻将规则不一,且竞技化程度相对较低,而日本麻将拥有世界上竞技化程度最高的麻将规则。天凤则是业界知名的高水平日本麻将平台。它吸引了全球近 33 万名麻将爱好者,其中不乏大量的专业麻将选手。
天凤平台规定,只有获批准的 AI 才可以进入“特上房”参与对战,目前在该房间可以达到的最高段位是十段。另一个房间是“凤凰房”,最高段位是十一段,仅对七段以上的人类付费玩家开放,目前不允许 AI 参与游戏。
除了 Suphx,还有另外两个 AI 也获准进入“特上房”比赛,分别是“爆打”和“NAGA25”。目前,Suphx 是唯一一个达到“特上房”最高段位的 AI。
由于单局麻将存在着很大的运气成分,所以天凤平台会通过“稳定段位”来衡量一位玩家的真实水平。在 5760 场比赛过后,Suphx 的稳定段位超过了8.7,不仅高于爆打和 NAGA,还超越了顶级人类选手(十段及以上)的整体稳定段位。

这些成就意味着,Suphx 在四个月内成长为了最强日麻 AI。日本麻将的爱好者和专业参赛选手,纷纷寻找着它背后的开发者,但一无所获。

(Suphx 的官方社交账号上,只有简单的介绍)
直到 8 月 29 日世界人工智能大会举行,Suphx 的身世才被公诸于世。当天上午,微软全球执行副总裁、微软人工智能及微软研究事业部负责人沈向洋博士对外宣布,Suphx 是微软亚洲研究院的工作成果,由刘铁岩博士带队研发。
刘铁岩博士是微软亚洲研究院副院长,长于深度学习、增强学习、分布式机器学习等领域。他的团队曾发布了微软分布式机器学习工具包(DMTK)、微软图引擎(Graph Engine)等开源项目。

(微软亚洲研究院副院长刘铁岩)对 AI 来说,为什么麻将比围棋、德州扑克更难?
“2017 年中旬,我们一个研究团队跟我说要做麻将 AI。我也不知道能不能成,因为相比象棋、围棋、德州扑克,麻将的难度更高。而且,他们打麻将水平都不怎么样。”微软全球资深副总裁、微软亚太研发集团主席兼微软亚洲研究院院长洪小文对 PingWest 品玩表示。
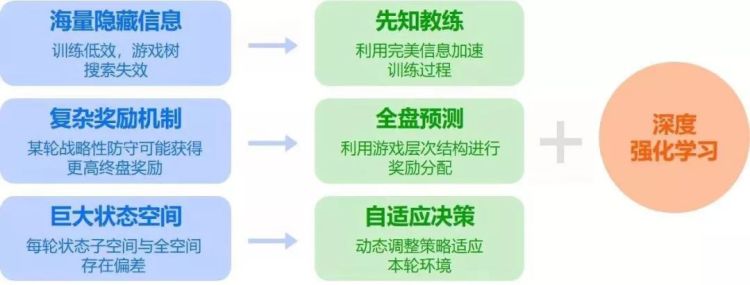
麻将的难,在于其属于“不完美信息游戏”(Imperfect-Information Games),让计算机擅长的搜索能力无法直接发挥,且具备复杂的奖励机制。
不完美信息游戏,是指游戏中信息暴露程度低。“围棋、象棋等棋类游戏,对局双方可以看到局面的所有信息,属于完美信息游戏(Perfect-Information Games);而扑克、桥牌、麻将等游戏,虽然每个参与者都能看到对手打过的牌,但并不知道对手的手牌和游戏的底牌,属于不完美信息游戏”。
在日本麻将中,每个玩家有 13 张手牌,另外还有 84 张底牌。对于一个玩家而言,他只知道自己手里的 13 张牌和之前已经打出来的牌,却无法知道别人的手牌和没有翻出来的底牌。所以,最多的时候一位玩家未知的牌有超过 120 张。
为了更好地解释不完美信息游戏,刘铁岩打了个比方:“如果把围棋这样的(完美信息)比赛比喻成一颗游戏树,那像麻将这样的比赛就是很多树组成的森林,参与者并不知道自己在哪棵树上。”
对于完美信息游戏,通常可以用“状态空间复杂度”和“游戏树复杂度”来衡量其游戏难度。
所谓“状态空间复杂度”,即游戏开始后,棋局进行过程中,所有符合规则的状态总数量。“例如棋类游戏中,每移动一枚棋子或捕获一个棋子,就创造了一个新的棋盘状态,所有这些棋盘状态构成游戏的状态空间”。
计算状态空间复杂度最常用的一种方法是,包含一些不符合规则或不可能在游戏中出现的状态,从而计算出状态空间的一个上界(Upper Bound)。例如在估计围棋状态数目上界的时候,允许出现棋面全部为白棋或者全部为黑棋的极端情况。
游戏树复杂度(GTC)代表了所有不同游戏路径的数目,是一个比状态空间复杂得多的衡量维度,因为同一个状态可以对应于不同的博弈顺序。
微软亚洲研究院的博客举了一个例子:下图中,两边的井字棋游戏都有有两个 X 和一个 O,属于同一状态。但这个状态可能由两种不同的方式形成,形成路径取决于第一个 X 的下子位置。

(井字棋游戏中统一状态的不同形成过程)
在完美信息棋牌游戏中,不管是状态空间复杂度,还是游戏树复杂度,围棋都远远超过其他棋牌类游戏。
而对于不完美信息游戏而言,衡量游戏难度的维度更加复杂,需要在状态空间复杂度的基础上引入一个新概念“信息集”。
举例而言,在扑克游戏中,玩家 A 拿了两张 K,玩家 B 拿了不同的牌对应不同的状态;但是从 A 的视角看,这些状态是不可区分的。
“我们把每组这种无法区分的游戏状态称为一个信息集。”刘铁岩介绍道。
完美信息游戏里所有信息都是已知的,每个信息集只包含一个游戏状态,因此它的信息集数目与状态空间数目是相等的。
而不完美信息游戏中,每个信息集包含若干个游戏状态,因此信息集数目通常小于状态空间的数目。
与信息集数目匹配的,是信息集的平均大小。这个概念指的是在信息集中平均有多少不可区分的游戏状态。
据微软亚洲研究院博客,信息集的数目反映了不完美信息游戏中,所有可能的决策节点的数目,而信息集的平均大小则反映了游戏中每个局面背后隐藏信息的数量。当对手的隐藏状态非常多时,传统的搜索算法基本上无从下手。
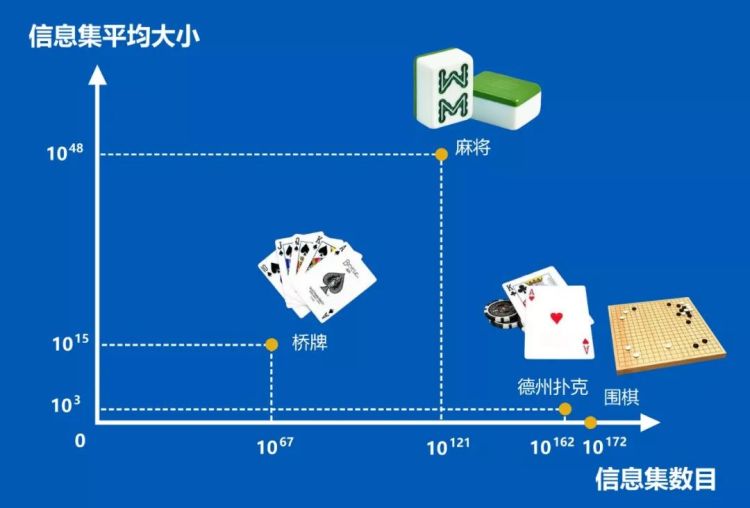
(围棋、德州扑克、桥牌和麻将的信息集数目和信息集平均大小对比)
围棋和德州扑克的信息集平均大小远远小于桥牌和麻将。AI 在围棋和德州扑克上的成功很大程度依赖于搜索算法,因为搜索可以最大程度地发挥计算机的计算优势。
桥牌和麻将中,由于信息集平均大小比较大,存在着较多隐藏信息,难以直接采用 AlphaGo 等棋盘游戏 AI 常用的蒙特卡洛树搜索算法。
此外,日本麻将有着复杂的奖励机制。日麻一轮游戏共包含 8 局,最后根据 8 局的得分总和进行排名,来形成最终影响段位的点数奖惩。玩家的段位越高,输掉比赛后扣掉的点数越多,因此有时麻将高手会策略性输牌。
刘铁岩举例道:“比如,A 玩家已经大比分领先第二名的情况下,在底 8 轮时就会相对保守,确保自己不会输。”这为构建高超的麻将 AI 策略带来了额外的挑战,AI 需要审时度势,把握进攻与防守的时机。
Suphx 是如何解决难题的?
项目一开始,刘铁岩团队用了一些“基线(Baseline)的解决办法”——尝试用 AlphaGo 和德州扑克上的方法解一解看看怎么样。
“麻将的种种特点决定了,很难直接利用 AlphaGo 等棋盘游戏 AI 常用的蒙特卡洛树搜索算法。”刘铁岩强调,“这激励我们要想出新的点子。”
在一年多的摸索期,刘铁岩团队基于深度强化学习技术,并且引入三项新技术来提升强化学习的效果。深度强化学习是深度学习和强化学习的结合。这项技术集合了深度学习在感知问题上强大的理解能力,以及强化学习的决策能力,通常用于解决现实场景中的复杂问题。
在深度强化学习的基础上,针对非完美信息游戏的特点,刘铁岩团队尝试用“先知教练”技术来提升强化学习的效果。
先知教练技术的基本思想是在自我博弈的训练阶段,利用不可见的一些隐藏信息来引导 AI 模型的训练方向,使其学习路径更加清晰、更加接近完美信息意义下的最优路径,从而倒逼 AI 模型更加深入地理解可见信息,从中找到有效的决策依据。
然而,在训练模型阶段采用的先知教练技术,在真正的实战中是没有的,这意味着训练和实战间存在着一个 Gap(差距)。
刘铁岩对 PingWest 品玩表示:“我们不能够保证一定把那个 Gap 给抹掉,比如说它在训练阶段能够看到不该看到的东西,实战中它是永远看不到的。这个信息的 Gap 我们是控制不了的,但是作为先知教练可以引导麻将 AI 不会走的太偏太远,会沿着我们想走的大方向走,。这个能保证训练过程的平稳性,对深度强化学习是非常重要的。”
针对信息集平均大小比较大这个特点,研究团队引入了自适应决策,对探索过程的多样性进行动态调控,让 Suphx 可以比传统算法更加充分地试探牌局状态的不同可能。
另外,对于日本麻将复杂的奖励机制,刘铁岩团队加入了全盘预测技术。
“这个预测器通过精巧的设计,可以理解每轮比赛对终盘的不同贡献,从而将终盘的奖励信号合理地分配回每一轮比赛之中,以便对自我博弈的过程进行更加直接而有效的指导,并使得 Suphx 可以学会一些具有大局观的高级技巧。”刘铁岩解释道。
总体而言,Suphx 使用的是深度强化学习这个大框架,但又加入了一些创新的技术点:先知教练、自适应决策和全盘预测。
在 2019 年 3 月上线 Suphx 平台之前,背后这一整套技术已经有了雏形,同时进行了大量的自我博弈。
“Suphx 在线上对战了 5760 场,但在线下自我博弈将近 2000 万场。”刘铁岩对 PingWest 品玩表示,“虽然自我博弈学到的信号数量很多,但是学到更多的是在自己身上怎么提高。5760 场里面我们学到别人打法的风格、以及实战中遇到的困难应该如何解决。”
刘铁岩透露,研究团队计划过一段时间会有一篇比较深入的科学论文跟大家分享, “在那里面大家会看到更多的细节”。
Suphx 背后的技术可以用在什么地方?
在 AI 进化的过程中,游戏 AI 一直相伴相生。1949 年开始,就有科学家研究算法,让计算机下国际象棋。双陆棋、国际跳棋、国际象棋、围棋等棋盘类游戏,都有人机对战的踪影。
1997 年 5 月 11 日,国际象棋 AI 深蓝在正常时限的比赛中,首次击败了等级分排名世界第一的棋手。这一天成为了人机对战的里程碑。
在洪小文看来,游戏 AI 对解决现实问题有着重要的研究意义:“现实世界更加复杂,而游戏均有一个清晰的规则、胜负判定条件和行动准则。如果不定规则,大家各做各的,就无法交流。研究也是这样的,将问题切成小问题,小问题里面规则定清楚,再往前走。”
麻将这一类不完美的信息游戏,正是现实生活中许多问题的映射。洪小文举例道:“追女朋友、企业经营、投资,都有大量的你不知道的隐藏信息。”
虽然 Suphx 面世不久,背后的技术还没有全部应用到实际问题中,但部分技术已经在做尝试。
“我们和华夏基金以及太平资产合作,做了一些实盘投资的尝试, 取得了非常好的效果。”刘铁岩告诉 PingWest 品玩,“我们用历史交易数据训练的 AI 模型,到真正市场上会面临完全不一样的数据,所以要动态地适应实际场景并做出改变,这个和 Suphx 里面的自适应决策是一脉相承的。”
尽管落地是研究的最终目标,但洪小文认为,纯粹的好奇心对研究人员来说更加宝贵:“做这项研究的时候,他们有没有想过未来可以怎么应用?八成是没有想,也不应该想,以好奇心驱动的研究是推动整个科研发展的基石。最明显的例子是,基础数学很多研究在当时都不见得有应用。”
有意思的是,天凤平台 CEO 角田真吾在被问到“为什么会欢迎 AI和人类对弈”时,给出了和洪小文几乎一样的措辞——纯粹出自于人类的好奇心。