来源:Lin_R
my.oschina.net/LinBigR/blog/857974
相信很多在linux平台工作的童鞋, 都很熟悉管道符 '|', 通过它, 我们能够很灵活的将几种不同的命令协同起来完成一件任务.就好像下面的命令:
echo123| awk '{print $0+123}'# 输出246
不过这次咱们不来说这些用法, 而是来探讨一些更加有意思的, 那就是 管道两边的数据流"实时性" 和 管道使用的小提示.
其实我们在利用管道的时候, 可能会不经意的去想, 我前一个命令的输出, 是全部处理完再通过管道传给第二个命令, 还是一边处理一边输出呢? 可能在大家是试验中或者工作经验中, 应该是左边的命令全部处理完再一次性交给右边的命令进行处理, 不光是大家, 我在最初接触管道时, 也曾有这么一个误会, 因为我们通过现象看到的就是这样.
但其实只要有简单了解过管道这工具, 应该都不难得出解释:
管道的定义管道是两边是同时进行, 也就是说, 左边的命令输出到管道, 管道的右边将马上进行处理.
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会堵塞,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
管道工作流程图
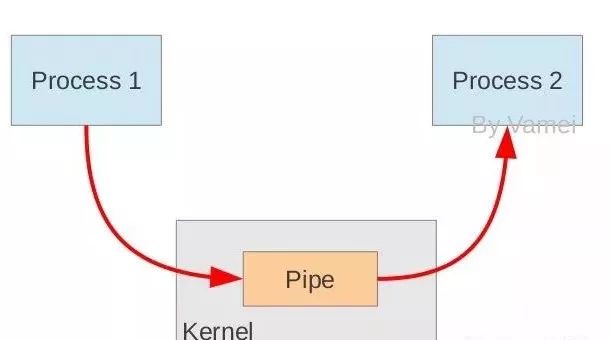
通过上面的解释可以看到, 假设 COMMAND1 | COMMAND2, 那么COMMAND1的标准输出, 将会被绑定到管道的写端, 而COMMAND2的标准输入将会绑定到管道的读端, 所以当COMMAND1一有输出, 将会马上通过管道传给COMMAND2, 我们先来做个实验验证下:
# 1.py
importtime
importsys
while1:
print'1111'
time.sleep( 3)
print'2222'
time.sleep( 3)
[root@iZ23pynfq19Z ~] # python 1 | cat
在上面的命令, 我们可以猜测下输出结果: 究竟是 睡眠6秒之后, 输出"1111222", 还是输出 "1111" 睡眠3秒, 再输出 "2222", 然后再睡眠3秒, 再输出"1111" 呢? 答案就是: 都不是! what! 这不可能, 大家可以尝试下, 我们会看到终端没反应了, 为什么呢? 这就要涉及到文件IO的缓冲方式了,关于文件IO, 可以参考我的另一篇文章: 浅谈文件描述符1和2, 在最下面的地方提到文件IO的三种缓冲方式:
- 全缓冲: 直到缓冲区被填满,才调用系统I/O函数, (一般是针对文件)
- 行缓冲: 遇到换行符就输出(标准输出)
- 无缓冲: 没有缓冲区,数据会立即读入或者输出到外存文件和设备上(标准错误
因为python是默认采用带缓冲的fputs(参考py27源码: fileobject.c: PyFile_WriteString函数), 又因为标准输出被改写到管道, 所以将会采取全缓冲的方式(shell 命令具体要看实现, 因为有些是用不带缓冲write实现,如果不带缓冲区,会直接写入管道), 所以将会采取全缓冲的方式, 也就是说, 直到缓冲区被填满, 或者手动显示调用flush刷入,才能看到输出.那我们可以将代码改写成下面两种方式吧
# 方式 1: 填满缓冲区, 我这边大小是 4096字节, 你们也可以试下这个值, 估计都一样
import time
import sys
while1:
print'1111'* 4096
time.sleep( 3)
print'2222'* 4096
time.sleep( 3)
# 方式 2: 手动刷入写队列
import time
import sys
while1:
print'1111'
sys. stdout. flush// 因为是标准输出, 所以直接通过sys的接口去 flush
time.sleep( 3)
print'2222'
sys. stdout. flush
time.sleep( 3)
输出结果:
# 第一种方式:
[root@iZ23pynfq19Z ~] # python 1 | cat
1111.....(超多 1, 刷屏了..)
睡眠 3秒..
2222.....(超多 2, 刷屏了..)
# 第二种方式:
[root@iZ23pynfq19Z ~] # python 1 | cat
1111
睡眠 3秒..
2222
睡眠 3秒..
1111
....
在这里我们已经能够得出结果, 如果像我们以前所想的那样, 要等到COMMAND1全部执行完才一次性输出给COMMAND2, 那么结果应该是无限堵塞..因为我的程序一直没有执行完..这样应该是不符合老前辈们设计初衷的, 因为这样可能会导致管道越来越大..然而管道也是有大小的~ 具体可以去看posix标准, 所以我们得出结论是: 只要COMMAND1的输出写入管道的写端(不管是缓冲区满还是手动flush), COMMAND2都将立刻得到数据并且马上处理.
那么 管道两边的数据流"实时性" 讨论到就先暂告一段落, 接下来将在这个基础上继续讨论: 管道使用的小提示.
在开始讨论前, 我想先引入一个专业术语, 也是我们偶尔会遇到的, 那就是: SIGPIPE 或者是一个更加具体的描述: broken pipe (管道破裂)
上面的专业术语都是跟管道读写规则息息相关的, 那咱们来看下 管道的读写规则吧:
- 当没有数据可读时
- O_NONBLOCK (未设置):read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
- O_NONBLOCK ( 设置 ) :read调用返回-1,errno值为EAGAIN。
- O_NONBLOCK (未设置):write调用阻塞,直到有进程读走数据
- O_NONBLOCK ( 设置 ):调用返回-1,errno值为EAGAIN
- 如果所有管道写端对应的文件描述符被关闭,则read返回0
- 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE
- 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
- 当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
在上面我们可以看到, 如果我们收到SIGPIPE信号, 那么一般情况就是读端被关闭, 但是写端却依旧尝试写入
咱们来重现下 SIGPIPE
#!/usr/bin/python
importtime
importsys
while1:
time.sleep( 10) # 手速不够快的童鞋可以将睡眠时间设置长点
print'1111'
sys.stdout.flush
这次执行命令需要考验手速了, 因为我们要赶在py醒过来之前, 将读端进程杀掉
python1| cat
------------------------
# 另一个终端
[root @iZ23pynfq19Z~] # ps -fe | grep -P 'cat|python'
root 107754074000: 05pts/ 200: 00: 00python 1
root 107764074000: 05pts/ 200: 00: 00cat # 读端进程
root 1083332581000: 06pts/ 000: 00: 00grep -P cat|python
[root @iZ23pynfq19Z~] # kill 10776
[root@iZ23pynfq19Z ~] # python 1 | cat
Traceback (most recent calllast):
File"1", line 6, in< module>
sys.stdout.flush
IOError: [Errno 32] Broken pipe
Terminated
从上图我们可以验证两个点:
- 当我们杀掉读端时, 写端会收到SIGPIPE而默认退出, 管道结束
- 当我们杀掉读端时, 写端的程序并不会马上收到SIGPIPE, 相反的, 只有真正写入管道写端时才会触发这个错误
如果写入一个 读端已经关闭的管道, 将会收到一个 SIGPIPE, 那读一个写端已经关闭的管道又会这样呢?
import time
import sys
# 这次我们不需要死循环, 因为我们想要写端快点关闭退出
time.sleep( 5)
print'1111'
sys. stdout. flush
# 因为我们想要 读端 等到足够长的时间, 让写端关闭, 所以我们需要利用awk先睡眠10秒
[root@iZ23pynfq19Z ~] # python 1.py | awk '{system("sleep 10");print 123}'
------------------------
[root@iZ23pynfq19Z ~] # ps -fe | grep -P 'awk|python'
root 117174074000: 20pts/ 200: 00: 00python 1.py
root 117184074000: 20pts/ 200: 00: 00awk { system( "sleep 10"); print123}
root 1172132581000: 20pts/ 000: 00: 00grep-P awk|python
# 5秒过后
[root@iZ23pynfq19Z ~] # ps -fe | grep -P 'awk|python'
root 116854074000: 20pts/ 200: 00: 00awk { system( "sleep 10"); print123}
root 1169832581000: 20pts/ 000: 00: 00grep-P awk|python
# 10秒过后
[root@iZ23pynfq19Z ~] # python 1 | awk '{system("sleep 10");print 123}'
123
在上面也已经证明了上文提到的读写规则: 如果所有管道写端对应的文件描述符被关闭,将产生EOF结束标志,read返回0, 程序退出。
总结
通过上面的理论和实验, 我们知道在使用管道时, 两边命令的数据传输过程, 以及对管道读写规则有了初步的认识, 希望我们以后在工作时, 再接触管道时, 能够更加有把握的去利用这一强大的工具。
